Notice
Recent Posts
Recent Comments
Link
munjji 님의 블로그
[컴퓨터구조] 1. 데이터와 표현 본문
비트와 바이트
- 컴퓨터는 10진법이 아닌 2진법을 사용해 정보를 저장하기 떄문에 0과 1만을 저장한다.
- 전기 신호의 전압이 일정 기준보다 높으면 1, 그렇지 않으면 0으로 변환하여 사용한다.
비트(bit)
- 비트는 0과 1을 표현할 수 있는 최소 단위
- 여러 개의 비트를 조합하여 데이터를 표현한다.
- ex) 000, 001, 010, ...
바이트(byte)
- 8비트를 한 묶음으로 표현한 단위
- 즉 1바이트 당 256(2^8)가지의 데이터 표현이 가능하다.
- 바이트를 더 큰 단위로 묶어 1KB, 1MB, 1GB, 1TB로 표현한다.
컴퓨터의 숫자 표현 - 정수
음수의 표현
부호 비트
- 컴퓨터는 n비트에서 가장 왼쪽의 비트(최상위 비트)를 부호 비트로 사용하여 음수를 표현한다.
- 부호 비트가 1이면 음수, 0이면 양수 또는 0이다.
- 예를 들어 4비트로 숫자를 표현한다고 할 때, 1011의 경우 최상위 비트가 1이므로 음수이다.
2의 보수
- 음수를 저장하기 위해 사용하는 방법이다.
- 모든 비트를 반전시키고 1을 더한다.
- 0011의 2의 보수는 1101 -> -3으로 인식한다.
- 3은 0011
- 2의 보수연산 1100
- 1을 더하면 1101
- n개의 비트로 표현할 수 있는 정수의 범위는 -2^(n-1) ~ 2^(n-1) - 1까지다.

컴퓨터의 숫자 표현 - 실수
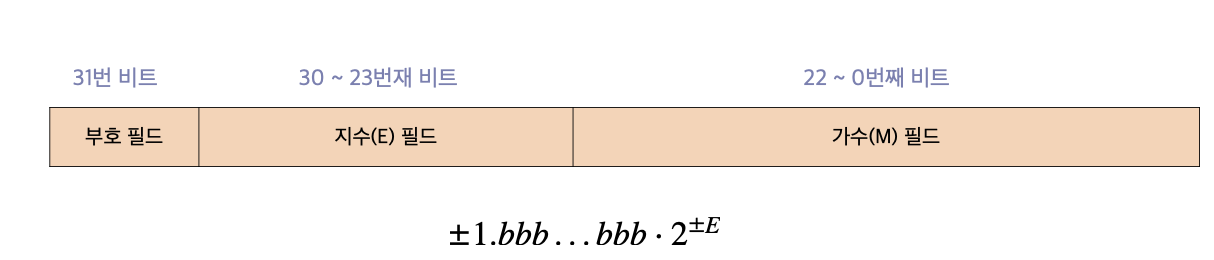
부동 소수점
- 국제표전 IEEE 754의 부동소수점 표현 방식으로 실수를 표현하고 저장한다.
- 32비트 기준으로 가장 최상위 비트를 부호 비트로 사용하고,
나머지 31개 비트를 지수 필드와 가수 필드로 분리한다. - 지수(E) 필드는 값의 범위를 나타내는 2의 거듭제곱 수를 저장한다.
- 23 ~ 30번째 비트, 256개 표현이 가능하다.
- 가수(M) 필드는 정밀도를 나타내기 위해 실제 숫자의 유효한 자릿수를 저장한다.
- 0 ~ 22번째 비트, 2^23개의 표현이 가능하다.
부동 소수점과 오차
- 실수는 2진수로 정확히 표현되지 않기 때문에 컴퓨터는 근사값으로 저장한다.
- 10진수의 0.1을 2진수로 변환하게 되면 0.0001100110011...과 같이 무한히 반복된다.
- 유한한 비트로는 이를 완전히 표현할 수 없어 근사값이 저장된다.
오차의 누적
- 실수 연산을 반복할 때 미세한 오차가 합산되어 누적된다.
- 누적된 오차는 특히 금융, 과학 계산 등에서 문제를 발생할 수 있다.
정밀도가 필요한 경우
Decimal (십진 임의정밀도 방식)
- 실수를 10진 가수와 10진 지수 형태로 저장함
- ex) 0.2 => 2 x 10^(-1)
- 내부적으로 큰 정수값과 소수 자릿수(scale)를 함께 보관함
- 0.1, 0.2와 같은 10진 유한소수를 정확히 표현
- 10진수 기반의 부동 소수점 (기준을 2가 아닌 10의 거듭제곱)
BigDecimal a = new BigDecimal("0.1");
BigDecimal b = new BigDecimal("0.2");
BigDecimal c = a.add(b); // 0.3 정확고정 소수점 (Fixed-point) 방식
- 실수를 정수로 변환하여 저장하고, 소수점 위치(스케일)는 고정함
- 모든 값이 동일한 자릿수 규칙을 따르므로 빠른 연산이 가능함
- 덧셈/뺄셈은 정수 연산과 동일하며, 곱셈/나눗셈 시 스케일 보정 필요
- 속도는 느리지만 정확하다.
- 소수점 자리를 고정시켜 정수로 계산한다.
SCALE = 100 # 소수 둘째 자리
price = int(19.99 * SCALE) # 1999
qty = int(3 * SCALE) # 300
total = (price * qty) // SCALE # 5997 -> 59.97컴퓨터의 문자 표현
아스키 코드
- 128개의 모든 조합을 제공하는 7비트 부호
- 오류 검출을 위한 패리티 부호에 해당하는 1비트를 포함해서 총 8비트로 구성한다.
- 하나의 문자는 하나의 번호에 대응한다.
- 문자 A를 숫자 65로 변환하는 것은 인코딩
- 숫자 65를 해석해서 문자 A로 변환하는 것은 디코딩

유니코드
- 아스키 코드는 미국의 표준이라 한국어, 일본어, 중국어 등의 외국어를 표현하는 데 한계
- 전 세계 문자를 동일한 방법으로 표현하기 위해 1995년 유니코드가 국제 표준으로 제정됨
- 초기엔 16비트였으나 표현할 문자나 이모티콘이 많아져 지금은 21비트로 늘렸다.
유니코드 표현 방법
- 비트를 4개씩 나눠서 16진법(4비트)으로 표현
- 16진법을 사용하는 경우 맨 앞에 U+를 붙여 표시
- (U+0000 ~ U+10FFFF)
- U+10FFFF은 10진법으로 약 111만
UTF-8
- 유니코드에 대해 가변 길이 인코딩을 수행
- 인코딩 결과는 1 ~ 4바이트가 가능
- 자주 쓰는 문자를 1바이트로 처리하여 용량을 절약
-
- 예를 들어 'A'는 아스키 코드의 65번으로 인코딩 시 01000001로 표현되는데 이는 'A'를 UTF-8로 변환해도 동일1바이트 문자는 아스키 코드와 호환된다.