
Notice
Recent Posts
Recent Comments
Link
munjji 님의 블로그
[정보처리기사] 3과목. 데이터베이스 구축 본문
개념적 설계(정보 모델링, 개념화)
- 정보의 구조를 얻기 위해 현실 세계에 대한 인식을 추상적 개념으로 표현하는 과정이다.
- 개념 스키마 모델링과 트랜잭션 모델링을 병행 수행한다.
논리적 설계(데이터 모델링)
- 자료를 특정 DBMS가 지원하는 논리적 자료 구조로 변환시키는 과정이다.
- 트랜잭션의 인터페이스를 설계한다.
- 개념 스키마를 평가 및 정제한다.
물리적 설계
- 논리적 구조로 표현된 데이터를 물리적 구조의 데이터로 변환하는 과정이다.
- 데이터베이스 파일의 저장 구조 및 액세스 경로를 결정한다.
- 저장 레코드의 형식, 순서, 접근 경로, 조회가 집중되는 레코드와 같은 정보를 사용한다.
데이터 모델에 표시할 요소
- 구조(Structure): 논리적으로 표현된 개체 타입들 간의 관계로서 데이터 구조 및 정적 성질을 표현함
- 연산(Operation): 데이터베이스에 저장된 실제 데이터를 처리하는 작업에 대한 명세로서 데이터베이스를 조작하는 기본 도구
- 제약 조건(Contraint): 데이터베이스에 저장될 수 있는 실제 데이터의 논리적인 제약 조건
E-R 다이어그램

튜플(Tuple)
- 릴레이션을 구성하는 각각의 행을 말한다.
- 튜플의 수 = 카디널리티(Cardinality)
속성(Attribute)
- 데이터베이스를 구성하는 가장 작은 논리적 단위이다.
- 속성의 수 = 디그리(Degree) = 차수
도메인(Domain)
- 하나의 애트리뷰트가 취할 수 있는 같은 타입의 원자값들의 집합이다.
릴레이션의 특징
- 한 릴레이션에는 똑같은 튜플이 포함될 수 없으므로 릴레이션에 포함된 튜플들은 모두 상이하다.
- 한 릴레이션에 포함된 튜플 사이에는 순서가 없다.
- 속성의 유일한 식별을 위해 속성의 명칭은 유일해야 한다.
- 속성의 값은 논리적으로 더 이상 쪼갤 수 없는 원자값만을 저장한다.
후보키(Candidate Key)
- 릴레이션을 구성하는 속성들 중에서 튜플을 유일하게 식별하기 위해 사용하는 속성들의 부분집합, 즉 기본키로 사용할 수 있는 속성들을 말한다.
- 릴레이션에 있는 모든 튜플에 대해서 유일성과 최소성을 만족시켜야 한다.
기본키(Primary Key)
- 후보키 중에서 특별히 선정된 주키로 중복된 값을 가질 수 없다.
- NULL값을 가질 수 없다.
대체키(Alternate Key)
- 후보키가 둘 이상일 때 기본키를 제외한 나머지 후보키를 의미한다.
- 보조키라고도 한다.
슈퍼키(Super Key)
- 한 릴레이션 내에 있는 속성들의 집합으로 구성된 키이다.
- 릴레이션을 구성하는 모든 튜플에 대해 유일성은 만족시키지만, 최소성은 만족시키지 못한다.
외래키(Foreign Key)
- 다른 릴레이션의 기본키를 참조하는 속성 또는 속성들의 집합을 의미한다.
- 한 릴레이션에 속한 속성 A와 참조 릴레이션의 기본키인 B가 동일한 도메인 상에서 정의되었을 떄의 속성 A를 외래키라고 한다.
무결성
- 개체 무결성 : 기본 테이블의 기본키를 구성하는 어떤 속성도 Null 값이나 중복값을 가질 수 없다는 규정
- 참조 무결성 : 외래키 값은 Null이거나 참조 릴레이션의 기본키 값과 동일해야 함. 즉 릴레이션은 참조할 수 없는 외래키 값을 가질 수 없다는 규정
관계대수
- 관계형 데이터베이스에서 원하는 정보와 그 정보를 검색하기 위해서 어떻게 유도하는가를 기술하는 절차적인 언어이다.
- 질의에 대한 해를 구하기 위해 수행해야 할 연산의 순서를 명시한다.
순수 관계 연산자 -Select
- 릴레이션에 존재하는 튜플 중에서 선택 조건을 만족하는 튜플의 부분집합을 구하여 새로운 릴레이션을 만드는 연산이다.
- 기호: 시그마(σ)
순수 관계 연산자 - Project
- 주어진 릴레이션에서 속성 리스트에 제시된 속성 값만을 추출하여 새로운 릴레이션을 만드는 연산이다.
- 기호: 파이(π)
순수 관계 연산자 - Join
- 공통 속성을 중심으로 두 개의 릴레이션을 하나로 합쳐서 새로운 릴레이션을 만드는 연산이다.
- 기호: ▷◁
순수 관계 연산자 -Division
- X⊃Y인 두 개의 릴레이션 R(X)와 S(Y)가 있을 때, R의 속성이 S의 속성값을 모두 가진 튜플에서 S가 가진 속성을 제외한 속성만을 구하는 연산이다.
- 기호: ÷
일반 집합 연산자 - 교차곱(Cartesian Product)
- 두 릴레이션에 있는 튜플들의 순서쌍을 구하는 연산이다.
- 교차곱의 디그리는 두 릴레이션의 디그리를 더한 것과 같다.
- 교차곱의 카디널리티는 두 릴레이션의 카디널리티를 곱한 것과 같다.
관계해석
- 관계 데이터 모델의 제안자인 코드(Codd)가 수학의 Predicate Calculus(술어 해석)에 기반을 두고 관계 데이터베이스를 위해 제안했다.
- 주요 기호
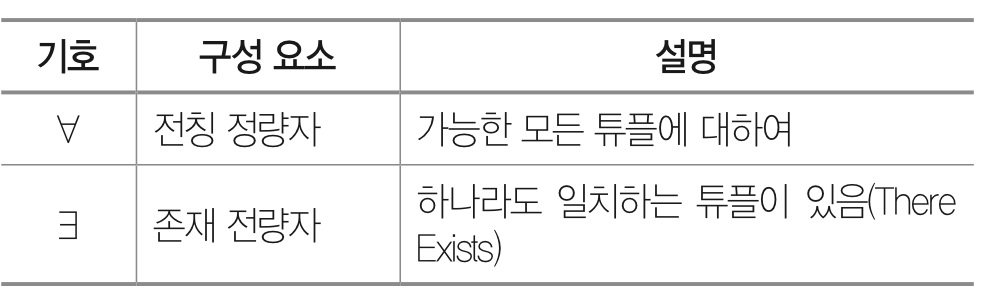
정규화(Normalization)
- 함수적 종속성 등의 종속성 이론을 이용하여 잘못 설계된 관계형 스키마를 더 작은 속성의 세트로 쪼개어 바람직한 스키마로 만들어 가는 과정이다.
- 논리적 설계 단계에서 수행한다.
- 데이터 중복을 배제하여 이상(Anomaly)의 발생 방지한다.
- 자료 저장 공간의 최소화가 가능하다.
이상(Anomaly)
- 정규화를 거치지 않으면 데이터베이스 내에 데이터들이 불필요하게 중복되어 릴레이션 조작 시 예기치 못한 곤란한 현상이 발생하는 것을 의미한다.
- 종류: 삽입 이상, 삭제 이상, 갱신 이상
정규화 과정

함수적 종속
- 데이터들이 어떤 기준값에 의해 종속되는 것을 의미한다.
- '학번'에 따라 '이름'이 결정될 때 '이름'을 '학번'에 함수 종속적이라고 하며 '학번 -> 이름'과 같이 쓴다.
이행적 종속 관계
A -> B이고 B -> C일 때 A -> C를 만족하는 관계를 의미한다.
반정규화(Denormalization)
- 시스템의 성능 향상, 개발 및 운영의 편의성 등을 위해 정규화된 데이터 모델을 통합, 중복, 분리하는 과정으로 의도적으로 정규화 원칙을 위배하는 행위다.
- 방법: 테이블 통합, 테이블 분할, 중복 테이블 추가, 중복 속성 추가 등
시스템 카탈로그(System Catalog)
- 시스템 그 자체에 관련이 있는 다양한 객체에 대한 정보를 포함하는 시스템 데이터베이스이다.
- 사용자가 시스템 카탈로그 내용을 검색할 수는 있지만 갱신할 수는 없다.
트랜잭션(Transaction) 정의
- 데이터베이스의 상태를 변환시키는 하나의 논리적 기능을 수행하기 위한 작업의 단위
- 한꺼번에 모두 수행되어야 할 일련의 연산
트랜잭션의 상태
- 활동(Active): 트랜잭션이 실행 중인 상태
- 실패(Failed): 트랜잭션 실행 중 오류가 발생하여 중단된 상태
- 철회(Aborted): 트랜잭션이 비정상적으로 종료되어 Rollback 연산을 수행한 상태
- 부분 완료(Partially Committed): 트랜잭션의 마지막 연산까지 완료했지만, Commit 연산이 실행되기 직전의 상태
- 완료(Committed): 트랜잭션이 성공적으로 종료되어 Commit 연산까지 수행한 상태
트랜잭션의 특성
- 원자성(Atomicity): 트랜잭션의 연산은 데이터베이스에 모두 반영되도록 완료(Commit)되든지 아니면 전혀 반영되지 않도록 복구(Rollback)되어야 함
- 일관성(Consistency): 트랜잭션이 그 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태로 변환함
- 독립성(Isolation): 둘 이상의 트랜잭션이 동시에 병행 실행되는 경우 어느 하나의 트랜잭션 실행 중에 다른 트랜잭션의 연산이 끼어들 수 없음
- 영속성(Durability): 성공적으로 완료된 트랜잭션의 결과는 시스템이 고장나더라도 영구적으로 반영되어야 함
인덱스(Index)
- 데이터 레코드를 더 빠르게 접근하기 위해 <키 값, 포인터>쌍으로 구성되는 데이터 구조이다.
- 데이터 정의어(DDL)를 이용해 사용자가 생성, 변경, 제거할 수 있다.
뷰(View)
- 기본 테이블로부터 유도된 이름을 가지는 가상 테이블이다.
- 뷰는 가상 테이블이기 때문에 물리적으로 구현되어 있지 않다.
- 뷰로 구성된 내용에 대한 삽입, 삭제, 갱신 연산에 제약이 따른다.
- 뷰를 정의할 때는 CREATE문, 제거할 때는 DROP문을 사용한다.
- 독립적인 인덱스를 가질 수 없다.
파티션(Partition)의 종류
- 범위 분할(Range Partitioning) : 지정한 열의 값을 기준으로 범위를 지정하여 분할함
예⃞ 일별, 월별, 분기별 등 - 해시 분할(Hash Partitioning) : 해시 함수를 적용한 결과값에 따라 데이터를 분할함
- 조합 분할(Composite Partitioning) : 범위 분할로 분할한 다음 해시 함수를 적용하여 다시 분할하는 방식
- 목록 분할(List Partitioning) : 지정한 열 값에 대한 목록을 만들어 이를 기준으로 분할함
- 라운드 로빈 분할(Round Robin Partitioning) : 레코드를 균일하게 분배하는 방식
분산 데이터베이스
- 논리적으로는 하나의 시스템에 속하지만 물리적으로는 네트워크를 통해 연결된 여러개의 컴퓨터 사이트에 분산되어 있는 데이터베이스를 말한다.
- 데이터베이스 설계 및 소프트웨어 개발이 어렵다.
- 분산 데이터베이스의 구성 요소
- 분산 처리기
- 분산 데이터베이스
- 통신 네트워크
분산 데이터베이스의 목표
- 위치 투명성(Location Transparency) : 액세스하려는 데이터베이스의 실제 위치를 알 필요 없이 단지 데이터베이스의 논리적인 명칭만으로 액세스할 수 있음
- 중복 투명성(Replication Transparency) : 동일 데이터가 여러 곳에 중복되어 있더라도 사용자는 마치 하나의 데이터만 존재하는 것처럼 사용하고, 시스템은 자동으로 여러 자료에 대한 작업을 수행함
- 병행 투명성(Concurrency Transparency) : 분산 데이터베이스와 관련된 다수의 트랜잭션들이 동시에 실행되더라도 그 트랜잭션의 결과는 영향을 받지 않음
- 장애 투명성(Failure Transparency) : 트랜잭션, DBMS, 네트워크, 컴퓨터 장애에도 불구하고 트랜잭션을 정확하게 처리함
암호화/복호화 과정
- 암호화 과정(Encryption): 암호화되지 않은 평문을 정보 보호를 위해 암호문으로 바꾸는 과정
- 복호화 과정(Decryption): 암호문을 원래의 평문으로 바꾸는 과정
접근 통제 기술
- 임의 접근통제(DAC; Discretionary Access Control): 데이터에 접근하는 사용자의 신원에 따라 접근 권한을 부여하는 방식
- 강제 접근통제(MAC; Mandatory Access Control): 주체와 객체의 등급을 비교하여 접근 권한을 부여하는 방식
- 역할기반 접근통제(RBAC; Role Based Access Control): 사용자의 역할에 따라 접근 권한을 부여하는 방식
벨 라파듈라(Bell-LaPadula Model)
- 군대 보안 레벨처럼 정보의 기밀성에 따라 상하 관계가 구분된 정보를 보호하기 위해 사용하는 접근제어 모델
- 보안 취급자의 등급을 기준으로 읽기 권한과 쓰기 권한이 제한된다.
DAS(Direct Attached Storage)
- 서버와 저장장치를 전용 케이블로 직접 연결하는 방식이다.
- 일반 가정에서 컴퓨터에 외장하드를 연결하는 것이 여기에 해당된다.
SAN(Storage Area Network)
- DAS의 빠른 처리와 NAS의 파일 공유 장점을 혼합한 방식이다.
- 서버와 저장장치를 연결하는 전용 네트워크를 별도로 구성한다.
DDL(데이터 정의어)
- 스키마, 도메인, 테이블, 뷰, 인덱스를 정의하거나 변경 또는 삭제할 때 사용하는 언어이다.
- CREATE : 스키마, 도메인, 테이블, 뷰, 인덱스를 정의함
- ALTER : TABLE에 대한 정의를 변경하는 데 사용함
- DROP : 스키마, 도메인, 테이블, 뷰, 인덱스를 삭제함
DML(데이터 조작어)
- 데이터베이스 사용자가 응용 프로그램이나 질의어를 통하여 저장된 데이터를 실질적으로 처리하는 데 사용되는 언어이다.
- SELECT : 테이블에서 조건에 맞는 튜플을 검색함
- INSERT : 테이블에 새로운 튜플을 삽입함
- DELETE : 테이블에서 조건에 맞는 튜플을 삭제함
- UPDATE : 테이블에서 조건에 맞는 튜플의 내용을 변경함
DCL(데이터 제어어)
- 데이터의 보안, 무결성, 회복, 병행 수행 제어 등을 정의하는 데 사용하는 언어이다.
- COMMIT : 명령에 의해 수행된 결과를 실제 물리적 디스크로 저장하고, 데이터베이스 조작 작업이 정상적으로 완료되었음을 관리자에게 알려줌
- ROLLBACK : 데이터베이스 조작 작업이 비정상적으로 종료되었을 때 원래의 상태로 복구함
- GRANT : 데이터베이스 사용자에게 사용 권한을 부여함
- REVOKE : 데이터베이스 사용자에게 사용 권한을 취소함
CREATE TABLE
- 테이블을 정의하는 명령문이다.
CREATE TABLE 테이블명
(속성명 데이터_타입 [DEFAULT 기본값] [NOT NULL], …
[, PRIMARY KEY(기본키_속성명, …)]
[, UNIQUE(대체키_속성명, …)]
[, FOREIGN KEY(외래키_속성명, …)]
[REFERENCES 참조테이블(기본키_속성명, …)]
[ON DELETE 옵션]
[ON UPDATE 옵션]
[, CONSTRAINT 제약조건명] [CHECK (조건식)]);ALTER TABLE
- 테이블에 대한 정의 변경하는 명령문이다.
ALTER TABLE 테이블명 ADD 속성명 데이터_타입 [DEFAULT ‘기본값’];
ALTER TABLE 테이블명 ALTER 속성명 [SET DEFAULT ‘기본값’];
ALTER TABLE 테이블명 DROP COLUMN 속성명 [CASCADE];DROP TABLE
- 기본 테이블을 제거하는 명령문이다.
DROP TABLE 테이블명 [CASCADE | RESTRICT];- CASCADE: 제거할 요소를 참조하는 다른 모든 개체를 함께 제거함
- RESTRICT: 다른 개체가 제거할 요소를 참조중일 때는 제거를 취소함
삽입문(INSERT INTO ~)
- 기본 테이블에 새로운 튜플을 삽입할 때 사용한다.
INSERT INTO 테이블명([속성명1, 속성명2,…])
VALUES (데이터1, 데이터2,… );삭제문(DELETE FROM ~)
- 기본 테이블에 있는 튜플들 중에서 특정 튜플(행)을 삭제할 때 사용한다.
DELETE
FROM 테이블명
[WHERE 조건];갱신문(UPDATE ~ SET ~)
- 기본 테이블에 있는 튜플들 중에서 특정 튜플의 내용을 변경할 때 사용한다.
UPDATE 테이블명
SET 속성명 = 데이터[, 속성명=데이터, …]
[WHERE 조건];데이터 조작문의 네 가지 유형
- SELECT(검색) : SELECT~ FROM~ WHERE~
- INSERT(삽입) : INSERT INTO~ VALUES~
- DELETE(삭제) : DELETE~ FROM~ WHERE~
- UPDATE(변경) : UPDATE~ SET~ WHERE~
SELECT문
SELECT [PREDICATE] [테이블명.]속성명1, [테이블명.]속성명2,…
FROM 테이블명1, 테이블명2,…
[WHERE 조건]
[GROUP BY 속성명1, 속성명2,…]
[HAVING 조건]
[ORDER BY 속성명 [ASC | DESC]];
- SELECT절
- Predicate : 불러올 튜플 수를 제한할 명령어
- DISTINCT : 중복된 튜플이 있으면 그 중 첫 번째 한 개만 검색
- 속성명 : 검색하여 불러올 속성(열) 및 수식들 - FROM절 : 질의에 의해 검색될 데이터들을 포함하는 테이블명
- WHERE절 : 검색할 조건
- GROUP BY절 : 특정 속성을 기준으로 그룹화하여 검색할 때 그룹화 할 속성
- HAVING절 : 그룹에 대한 조건
- ORDER BY절
- 속성명 : 정렬의 기준이 되는 속성명
- [ASC | DESC] : 정렬 방식(ASC는 오름차순, DESC 또는 생략하면 내림차순)
조건 연산자 - LIKE
- 대표 문자를 이용해 지정된 속성의 값이 문자 패턴과 일치하는 튜플을 검색하기 위해 사용된다.
- 대표문자
- % : 모든 문자를 대표함
- _ : 문자 하나를 대표함
- # : 숫자 하나를 대표함
조건 연산자 - BETWEEN
- 지정된 속성이 두 숫자 사이의 값을 가지는 튜플을 검색하기 위해 사용된다.
- 예: 생일이 ‘01/09/69’에서 ‘10/22/73’ 사이인 자료만 검색
→ WHERE 생일 BETWEEN #01/09/69# AND #10/22/73#
그룹 함수
- GROUP BY절에 지정된 그룹별로 속성의 값을 집계할 때 사용된다.
- COUNT/SUM/MIN/MAX/AVG(속성명): 그룹별 튜플 수/합계/최소/최대/평균값을 구하는 함수
집합 연산자의 종류
- UNION: 두 조회 결과를 통합해 모두 출력하되, 중복된 행은 한 번만 출력함
- UNION ALL: 두 조회 결과를 통해 모두 출력하되, 중복된 행도 그대로 출력함
- INTERSECT: 두 조회 결과 중 공통된 행만 출력
- EXCEPT: 첫 번째 조회 결과에서 두 번째 조회 결과를 제외한 행을 출력함
트리커(Trigger)
- 데이터 삽입, 갱신, 삭제 등의 이벤트가 발생할 때마다 관련 작업이 자동으로 수행되는 절차형 SQL이다.
'CS' 카테고리의 다른 글
| [정보처리기사] 5과목. 정보시스템 구축 관리 (0) | 2026.03.13 |
|---|---|
| [정보처리기사] 2과목. 소프트웨어 개발 (0) | 2026.03.12 |
| [정보처리기사] 1과목. 소프트웨어 설계 (0) | 2026.03.11 |
| [CS] 메시지 큐 (0) | 2026.03.06 |
| [CS] 비동기 처리 (0) | 2026.03.05 |
'CS' Related Articles
more

